Running Apache Flink on Amazon Elastic Mapreduce
I love really Amazon EMR. Over the years it’s grown from being “Hadoop on-demand” to a full-fledged cluster management system for running OSS big-data apps (Hadoop MR of course, but also Spark, Hue, Hive, Pig, Oozie and more).
While Hadoop out of the box supports reading from S3, EMR has a proprietary implementation called EMRFS that has some nice features. For those reasons, it’s really the best Hadoop cluster to use if you’re storing your data in S3.
Lately I’ve been experimenting a lot with Apache Flink to replace MR as the excution fabric. At work, we have many, many jobs written in Scalding. Flink can execute Scalding jobs with some very simple modifications which was a great way to move our jobs from MR to a more memory-centric data processing model.
However, we really wanted to run our jobs on EMR using Flink. Flink is not an option for EMR (yet) but can we still get our jobs to run? Let’s see!
Start an EMR cluster
The first thing we need is an EMR cluster. You can launch a small test cluster for very cheap. Once it’s running, let’s ssh onto it and see what’s going on.
ihummel at mm-mac-3270 in ~
$ ssh hadoop@ec2-54-226-25-85.compute-1.amazonaws.com
Last login: Wed Jan 6 16:33:01 2016 from 172.85.47.138
__| __|_ )
_| ( / Amazon Linux AMI
___|\___|___|
https://aws.amazon.com/amazon-linux-ami/2015.09-release-notes/
23 package(s) needed for security, out of 49 available
Run "sudo yum update" to apply all updates.
EEEEEEEEEEEEEEEEEEEE MMMMMMMM MMMMMMMM RRRRRRRRRRRRRRR
E::::::::::::::::::E M:::::::M M:::::::M R::::::::::::::R
EE:::::EEEEEEEEE:::E M::::::::M M::::::::M R:::::RRRRRR:::::R
E::::E EEEEE M:::::::::M M:::::::::M RR::::R R::::R
E::::E M::::::M:::M M:::M::::::M R:::R R::::R
E:::::EEEEEEEEEE M:::::M M:::M M:::M M:::::M R:::RRRRRR:::::R
E::::::::::::::E M:::::M M:::M:::M M:::::M R:::::::::::RR
E:::::EEEEEEEEEE M:::::M M:::::M M:::::M R:::RRRRRR::::R
E::::E M:::::M M:::M M:::::M R:::R R::::R
E::::E EEEEE M:::::M MMM M:::::M R:::R R::::R
EE:::::EEEEEEEE::::E M:::::M M:::::M R:::R R::::R
E::::::::::::::::::E M:::::M M:::::M RR::::R R::::R
EEEEEEEEEEEEEEEEEEEE MMMMMMM MMMMMMM RRRRRRR RRRRRR
Hadoop ships with some example MR programs we can run. But first let’s get some data.
The EMR team has some sample data available at ``. We can download it using hdfs to inspect locally.
[hadoop@ip-10-5-190-199 ~]$ hdfs dfs -copyToLocal s3://elasticmapreduce/samples/wordcount/input/0001 /tmp/0001
16/01/06 16:41:53 INFO fs.EmrFileSystem: Consistency disabled, using com.amazon.ws.emr.hadoop.fs.s3n.S3NativeFileSystem as filesystem implementation
16/01/06 16:41:54 INFO s3n.S3NativeFileSystem: Opening 's3://elasticmapreduce/samples/wordcount/input/0001' for reading
Let’s check out our data:
[hadoop@ip-10-5-190-199 ~]$ head /tmp/0001
CIA -- The World Factbook -- Country Listing
World Factbook Home
The World Factbook
Country Listing
A
B C D E
F G H I
J K L M
Ok, now let’s run our MR example! We’re just going to tell Hadoop to read directly from S3 and write to the cluster’s HDFS.
[hadoop@ip-10-5-190-199 ~]$ hadoop jar /usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar wordcount s3://elasticmapreduce/samples/wordcount/input/0001 hdfs:///example
16/01/06 16:44:29 INFO fs.EmrFileSystem: Consistency disabled, using com.amazon.ws.emr.hadoop.fs.s3n.S3NativeFileSystem as filesystem implementation
16/01/06 16:44:29 INFO metrics.MetricsSaver: MetricsConfigRecord disabledInCluster: false instanceEngineCycleSec: 60 clusterEngineCycleSec: 60 disableClusterEngine: false maxMemoryMb: 3072 maxInstanceCount: 500 lastModified: 1452097718671
16/01/06 16:44:29 INFO metrics.MetricsSaver: Created MetricsSaver j-1IMQSYJE90DQ8:i-bb0ae232:RunJar:14396 period:60 /mnt/var/em/raw/i-bb0ae232_20160106_RunJar_14396_raw.bin
16/01/06 16:44:30 INFO client.RMProxy: Connecting to ResourceManager at ip-10-5-190-199.ec2.internal/10.5.190.199:8032
16/01/06 16:44:31 INFO input.FileInputFormat: Total input paths to process : 1
16/01/06 16:44:31 INFO lzo.GPLNativeCodeLoader: Loaded native gpl library
16/01/06 16:44:31 INFO lzo.LzoCodec: Successfully loaded & initialized native-lzo library [hadoop-lzo rev 41f4e6be3ac5d6676a3464f77de79a33e8fdd9f3]
16/01/06 16:44:31 INFO mapreduce.JobSubmitter: number of splits:1
16/01/06 16:44:31 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1452097713191_0001
16/01/06 16:44:32 INFO impl.YarnClientImpl: Submitted application application_1452097713191_0001
16/01/06 16:44:32 INFO mapreduce.Job: The url to track the job: http://ip-10-5-190-199.ec2.internal:20888/proxy/application_1452097713191_0001/
16/01/06 16:44:32 INFO mapreduce.Job: Running job: job_1452097713191_0001
16/01/06 16:44:40 INFO mapreduce.Job: Job job_1452097713191_0001 running in uber mode : false
16/01/06 16:44:40 INFO mapreduce.Job: map 0% reduce 0%
16/01/06 16:44:51 INFO mapreduce.Job: map 100% reduce 0%
16/01/06 16:44:58 INFO mapreduce.Job: map 100% reduce 14%
16/01/06 16:44:59 INFO mapreduce.Job: map 100% reduce 43%
16/01/06 16:45:01 INFO mapreduce.Job: map 100% reduce 57%
16/01/06 16:45:02 INFO mapreduce.Job: map 100% reduce 71%
16/01/06 16:45:03 INFO mapreduce.Job: map 100% reduce 86%
16/01/06 16:45:05 INFO mapreduce.Job: map 100% reduce 100%
16/01/06 16:45:05 INFO mapreduce.Job: Job job_1452097713191_0001 completed successfully
16/01/06 16:45:05 INFO mapreduce.Job: Counters: 54
File System Counters
FILE: Number of bytes read=354158
FILE: Number of bytes written=1605799
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=115
HDFS: Number of bytes written=407671
HDFS: Number of read operations=23
HDFS: Number of large read operations=0
HDFS: Number of write operations=14
S3: Number of bytes read=2392524
S3: Number of bytes written=0
S3: Number of read operations=0
S3: Number of large read operations=0
S3: Number of write operations=0
Job Counters
Launched map tasks=1
Launched reduce tasks=7
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=48054
Total time spent by all reduces in occupied slots (ms)=451812
Total time spent by all map tasks (ms)=8009
Total time spent by all reduce tasks (ms)=37651
Total vcore-seconds taken by all map tasks=8009
Total vcore-seconds taken by all reduce tasks=37651
Total megabyte-seconds taken by all map tasks=11532960
Total megabyte-seconds taken by all reduce tasks=108434880
Map-Reduce Framework
Map input records=44415
Map output records=322372
Map output bytes=3456594
Map output materialized bytes=354130
Input split bytes=115
Combine input records=322372
Combine output records=39791
Reduce input groups=39791
Reduce shuffle bytes=354130
Reduce input records=39791
Reduce output records=39791
Spilled Records=79582
Shuffled Maps =7
Failed Shuffles=0
Merged Map outputs=7
GC time elapsed (ms)=600
CPU time spent (ms)=18350
Physical memory (bytes) snapshot=2030002176
Virtual memory (bytes) snapshot=23555211264
Total committed heap usage (bytes)=2729443328
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=2392524
File Output Format Counters
Bytes Written=407671
You can see that the job started and was run by YARN.
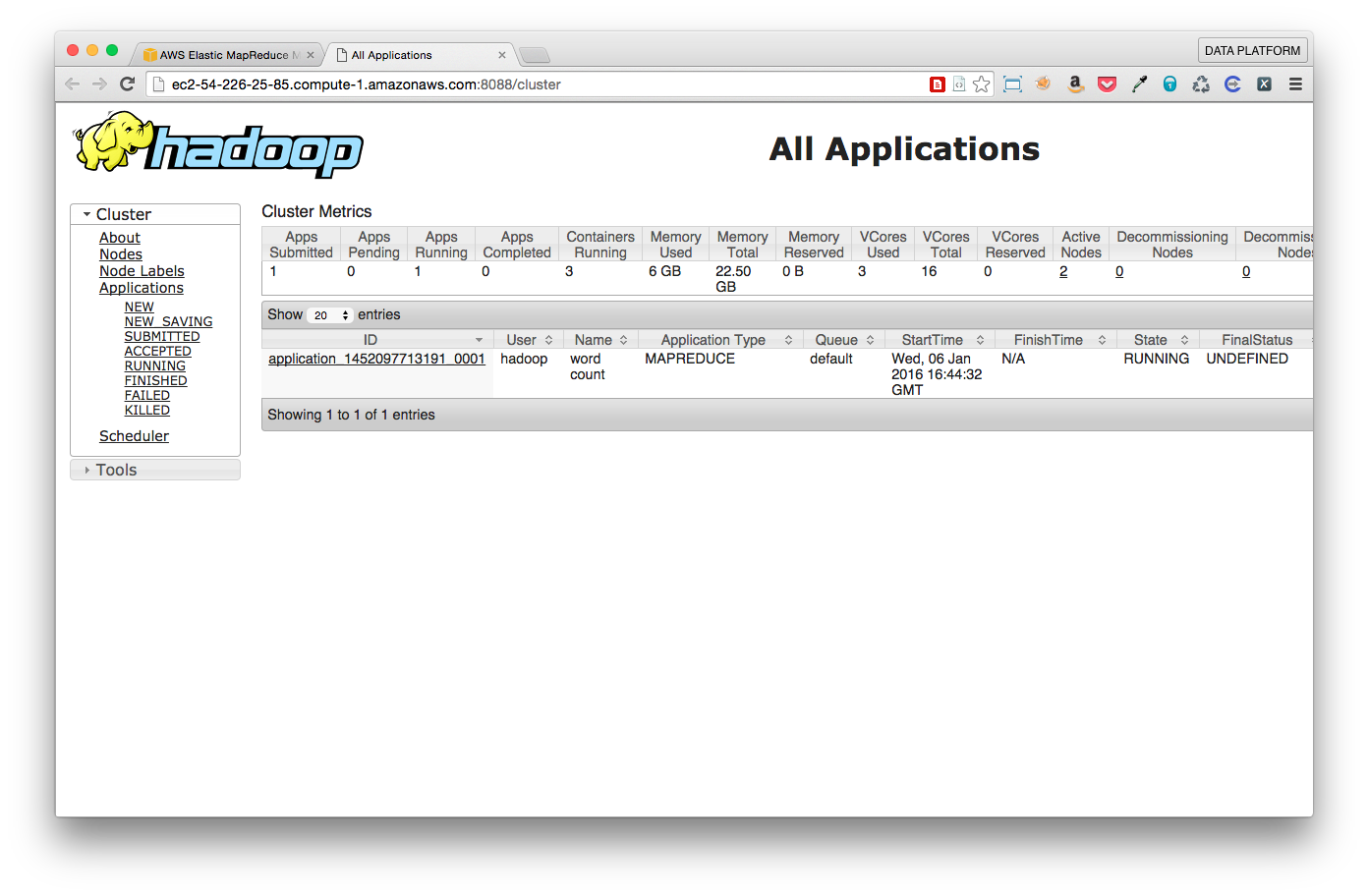
Let’s have a look at our data:
[hadoop@ip-10-5-190-199 ~]$ hdfs dfs -cat hdfs:///example/* | head
"East"; 1
"Force 1
"Quartet" 1
"Tigers." 1
"absolute 1
"code 5
"combat 1
"disruptive" 1
"farmers' 1
"load-shedding" 1
Cool. It worked. Now can we do somethign similar with Flink?
Installing Flink
We can just download it and unpack it on the master node.
[hadoop@ip-10-5-190-199 ~]$ curl http://apache.arvixe.com/flink/flink-0.10.1/flink-0.10.1-bin-hadoop26-scala_2.11.tgz | tar xz
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 84.2M 100 84.2M 0 0 45.1M 0 0:00:01 0:00:01 --:--:-- 45.1M
[hadoop@ip-10-5-190-199 ~]$ ls
flink-0.10.1
You should download a version of Flink compatible with the EMR-installed Hadoop and Scala. For EMR 4.2.0 you can use:
- Hadoop 2.6.0
- Scala 2.11
Running the Flink example
Ok, Flink also has a wordcount example we can try and run now. Spoiler alert, reading from S3 directly isn’t going to work yet, so let’s first copy our data.
[hadoop@ip-10-5-190-199 ~]$ hdfs dfs -mkdir hdfs:///input
[hadoop@ip-10-5-190-199 ~]$ hdfs dfs -cp s3://elasticmapreduce/samples/wordcount/input/0001 hdfs:///input/
16/01/06 16:52:40 INFO fs.EmrFileSystem: Consistency disabled, using com.amazon.ws.emr.hadoop.fs.s3n.S3NativeFileSystem as filesystem implementation
16/01/06 16:52:41 INFO s3n.S3NativeFileSystem: Opening 's3://elasticmapreduce/samples/wordcount/input/0001' for reading
[hadoop@ip-10-5-190-199 ~]$ hdfs dfs -cat hdfs:///input/* | head
CIA -- The World Factbook -- Country Listing
World Factbook Home
The World Factbook
Country Listing
A
B C D E
F G H I
J K L M
Cool. Now to run wordcount on Flink.
[hadoop@ip-10-5-190-199 ~]$ HADOOP_CONF_DIR=/etc/hadoop/conf flink-0.10.1/bin/flink run -m yarn-cluster -yn 3 -yjm 1024 -ytm 4096 flink-0.10.1/examples/WordCount.jar hdfs:///input hdfs:///flink-output
YARN cluster mode detected. Switching Log4j output to console
16:54:36,727 INFO org.apache.hadoop.yarn.client.RMProxy - Connecting to ResourceManager at ip-10-5-190-199.ec2.internal/10.5.190.199:8032
16:54:36,934 INFO org.apache.flink.client.FlinkYarnSessionCli - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.FlinkYarnClient to locate the jar
16:54:36,945 INFO org.apache.flink.yarn.FlinkYarnClient - Using values:
16:54:36,947 INFO org.apache.flink.yarn.FlinkYarnClient - TaskManager count = 3
16:54:36,948 INFO org.apache.flink.yarn.FlinkYarnClient - JobManager memory = 1024
16:54:36,948 INFO org.apache.flink.yarn.FlinkYarnClient - TaskManager memory = 4096
16:54:37,662 INFO org.apache.flink.yarn.Utils - Copying from file:/home/hadoop/flink-0.10.1/lib/flink-dist_2.11-0.10.1.jar to hdfs://ip-10-5-190-199.ec2.internal:8020/user/hadoop/.flink/application_1452097713191_0002/flink-dist_2.11-0.10.1.jar
16:54:38,388 INFO org.apache.flink.yarn.Utils - Copying from /home/hadoop/flink-0.10.1/conf/flink-conf.yaml to hdfs://ip-10-5-190-199.ec2.internal:8020/user/hadoop/.flink/application_1452097713191_0002/flink-conf.yaml
16:54:38,402 INFO org.apache.flink.yarn.Utils - Copying from file:/home/hadoop/flink-0.10.1/conf/logback.xml to hdfs://ip-10-5-190-199.ec2.internal:8020/user/hadoop/.flink/application_1452097713191_0002/logback.xml
16:54:38,420 INFO org.apache.flink.yarn.Utils - Copying from file:/home/hadoop/flink-0.10.1/conf/log4j.properties to hdfs://ip-10-5-190-199.ec2.internal:8020/user/hadoop/.flink/application_1452097713191_0002/log4j.properties
16:54:38,441 INFO org.apache.flink.yarn.FlinkYarnClient - Submitting application master application_1452097713191_0002
16:54:38,465 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl - Submitted application application_1452097713191_0002
16:54:38,465 INFO org.apache.flink.yarn.FlinkYarnClient - Waiting for the cluster to be allocated
16:54:38,467 INFO org.apache.flink.yarn.FlinkYarnClient - Deploying cluster, current state ACCEPTED
16:54:39,469 INFO org.apache.flink.yarn.FlinkYarnClient - Deploying cluster, current state ACCEPTED
16:54:40,471 INFO org.apache.flink.yarn.FlinkYarnClient - Deploying cluster, current state ACCEPTED
16:54:41,473 INFO org.apache.flink.yarn.FlinkYarnClient - Deploying cluster, current state ACCEPTED
16:54:42,475 INFO org.apache.flink.yarn.FlinkYarnClient - Deploying cluster, current state ACCEPTED
16:54:43,477 INFO org.apache.flink.yarn.FlinkYarnClient - YARN application has been deployed successfully.
16:54:43,482 INFO org.apache.flink.yarn.FlinkYarnCluster - Start actor system.
16:54:44,116 INFO org.apache.flink.yarn.FlinkYarnCluster - Start application client.
YARN cluster started
JobManager web interface address http://ip-10-5-190-199.ec2.internal:20888/proxy/application_1452097713191_0002/
Waiting until all TaskManagers have connected
16:54:44,134 INFO org.apache.flink.yarn.ApplicationClient - Notification about new leader address akka.tcp://flink@10.180.86.100:45496/user/jobmanager with session ID null.
No status updates from the YARN cluster received so far. Waiting ...
16:54:44,140 INFO org.apache.flink.yarn.ApplicationClient - Received address of new leader akka.tcp://flink@10.180.86.100:45496/user/jobmanager with session ID null.
16:54:44,142 INFO org.apache.flink.yarn.ApplicationClient - Disconnect from JobManager null.
16:54:44,147 INFO org.apache.flink.yarn.ApplicationClient - Trying to register at JobManager akka.tcp://flink@10.180.86.100:45496/user/jobmanager.
16:54:44,386 INFO org.apache.flink.yarn.ApplicationClient - Successfully registered at the JobManager Actor[akka.tcp://flink@10.180.86.100:45496/user/jobmanager#-344327648]
TaskManager status (0/3)
TaskManager status (0/3)
TaskManager status (0/3)
TaskManager status (0/3)
TaskManager status (0/3)
TaskManager status (0/3)
TaskManager status (0/3)
TaskManager status (0/3)
TaskManager status (0/3)
TaskManager status (0/3)
TaskManager status (0/3)
TaskManager status (0/3)
TaskManager status (2/3)
TaskManager status (2/3)
TaskManager status (2/3)
TaskManager status (2/3)
All TaskManagers are connected
Using the parallelism provided by the remote cluster (3). To use another parallelism, set it at the ./bin/flink client.
01/06/2016 16:54:53 Job execution switched to status RUNNING.
01/06/2016 16:54:53 CHAIN DataSource (at getTextDataSet(WordCount.java:142) (org.apache.flink.api.java.io.TextInputFormat)) -> FlatMap (FlatMap at main(WordCount.java:69)) -> Combine(SUM(1), at main(WordCount.java:72)(1/3) switched to SCHEDULED
01/06/2016 16:54:53 CHAIN DataSource (at getTextDataSet(WordCount.java:142) (org.apache.flink.api.java.io.TextInputFormat)) -> FlatMap (FlatMap at main(WordCount.java:69)) -> Combine(SUM(1), at main(WordCount.java:72)(1/3) switched to DEPLOYING
01/06/2016 16:54:53 CHAIN DataSource (at getTextDataSet(WordCount.java:142) (org.apache.flink.api.java.io.TextInputFormat)) -> FlatMap (FlatMap at main(WordCount.java:69)) -> Combine(SUM(1), at main(WordCount.java:72)(2/3) switched to SCHEDULED
01/06/2016 16:54:53 CHAIN DataSource (at getTextDataSet(WordCount.java:142) (org.apache.flink.api.java.io.TextInputFormat)) -> FlatMap (FlatMap at main(WordCount.java:69)) -> Combine(SUM(1), at main(WordCount.java:72)(2/3) switched to DEPLOYING
01/06/2016 16:54:53 CHAIN DataSource (at getTextDataSet(WordCount.java:142) (org.apache.flink.api.java.io.TextInputFormat)) -> FlatMap (FlatMap at main(WordCount.java:69)) -> Combine(SUM(1), at main(WordCount.java:72)(3/3) switched to SCHEDULED
01/06/2016 16:54:53 CHAIN DataSource (at getTextDataSet(WordCount.java:142) (org.apache.flink.api.java.io.TextInputFormat)) -> FlatMap (FlatMap at main(WordCount.java:69)) -> Combine(SUM(1), at main(WordCount.java:72)(3/3) switched to DEPLOYING
01/06/2016 16:54:53 CHAIN DataSource (at getTextDataSet(WordCount.java:142) (org.apache.flink.api.java.io.TextInputFormat)) -> FlatMap (FlatMap at main(WordCount.java:69)) -> Combine(SUM(1), at main(WordCount.java:72)(2/3) switched to RUNNING
01/06/2016 16:54:53 CHAIN DataSource (at getTextDataSet(WordCount.java:142) (org.apache.flink.api.java.io.TextInputFormat)) -> FlatMap (FlatMap at main(WordCount.java:69)) -> Combine(SUM(1), at main(WordCount.java:72)(1/3) switched to RUNNING
01/06/2016 16:54:53 CHAIN DataSource (at getTextDataSet(WordCount.java:142) (org.apache.flink.api.java.io.TextInputFormat)) -> FlatMap (FlatMap at main(WordCount.java:69)) -> Combine(SUM(1), at main(WordCount.java:72)(3/3) switched to RUNNING
01/06/2016 16:54:55 Reduce (SUM(1), at main(WordCount.java:72)(1/3) switched to SCHEDULED
01/06/2016 16:54:55 Reduce (SUM(1), at main(WordCount.java:72)(3/3) switched to SCHEDULED
01/06/2016 16:54:55 Reduce (SUM(1), at main(WordCount.java:72)(3/3) switched to DEPLOYING
01/06/2016 16:54:55 Reduce (SUM(1), at main(WordCount.java:72)(2/3) switched to SCHEDULED
01/06/2016 16:54:55 Reduce (SUM(1), at main(WordCount.java:72)(1/3) switched to DEPLOYING
01/06/2016 16:54:55 Reduce (SUM(1), at main(WordCount.java:72)(2/3) switched to DEPLOYING
01/06/2016 16:54:55 CHAIN DataSource (at getTextDataSet(WordCount.java:142) (org.apache.flink.api.java.io.TextInputFormat)) -> FlatMap (FlatMap at main(WordCount.java:69)) -> Combine(SUM(1), at main(WordCount.java:72)(1/3) switched to FINISHED
01/06/2016 16:54:55 Reduce (SUM(1), at main(WordCount.java:72)(3/3) switched to RUNNING
01/06/2016 16:54:55 Reduce (SUM(1), at main(WordCount.java:72)(1/3) switched to RUNNING
01/06/2016 16:54:55 Reduce (SUM(1), at main(WordCount.java:72)(2/3) switched to RUNNING
01/06/2016 16:54:57 CHAIN DataSource (at getTextDataSet(WordCount.java:142) (org.apache.flink.api.java.io.TextInputFormat)) -> FlatMap (FlatMap at main(WordCount.java:69)) -> Combine(SUM(1), at main(WordCount.java:72)(2/3) switched to FINISHED
01/06/2016 16:54:57 CHAIN DataSource (at getTextDataSet(WordCount.java:142) (org.apache.flink.api.java.io.TextInputFormat)) -> FlatMap (FlatMap at main(WordCount.java:69)) -> Combine(SUM(1), at main(WordCount.java:72)(3/3) switched to FINISHED
01/06/2016 16:54:57 DataSink (CsvOutputFormat (path: hdfs:/flink-output, delimiter: ))(3/3) switched to SCHEDULED
01/06/2016 16:54:57 DataSink (CsvOutputFormat (path: hdfs:/flink-output, delimiter: ))(3/3) switched to DEPLOYING
01/06/2016 16:54:57 DataSink (CsvOutputFormat (path: hdfs:/flink-output, delimiter: ))(3/3) switched to RUNNING
01/06/2016 16:54:57 Reduce (SUM(1), at main(WordCount.java:72)(3/3) switched to FINISHED
01/06/2016 16:54:57 DataSink (CsvOutputFormat (path: hdfs:/flink-output, delimiter: ))(1/3) switched to SCHEDULED
01/06/2016 16:54:57 DataSink (CsvOutputFormat (path: hdfs:/flink-output, delimiter: ))(1/3) switched to DEPLOYING
01/06/2016 16:54:57 DataSink (CsvOutputFormat (path: hdfs:/flink-output, delimiter: ))(2/3) switched to SCHEDULED
01/06/2016 16:54:57 DataSink (CsvOutputFormat (path: hdfs:/flink-output, delimiter: ))(2/3) switched to DEPLOYING
01/06/2016 16:54:57 DataSink (CsvOutputFormat (path: hdfs:/flink-output, delimiter: ))(2/3) switched to RUNNING
01/06/2016 16:54:57 DataSink (CsvOutputFormat (path: hdfs:/flink-output, delimiter: ))(1/3) switched to RUNNING
01/06/2016 16:54:57 Reduce (SUM(1), at main(WordCount.java:72)(2/3) switched to FINISHED
01/06/2016 16:54:57 Reduce (SUM(1), at main(WordCount.java:72)(1/3) switched to FINISHED
01/06/2016 16:54:57 DataSink (CsvOutputFormat (path: hdfs:/flink-output, delimiter: ))(3/3) switched to FINISHED
01/06/2016 16:54:58 DataSink (CsvOutputFormat (path: hdfs:/flink-output, delimiter: ))(1/3) switched to FINISHED
01/06/2016 16:54:58 DataSink (CsvOutputFormat (path: hdfs:/flink-output, delimiter: ))(2/3) switched to FINISHED
01/06/2016 16:54:58 Job execution switched to status FINISHED.
Shutting down YARN cluster
16:54:58,219 INFO org.apache.flink.yarn.FlinkYarnCluster - Sending shutdown request to the Application Master
16:54:58,220 INFO org.apache.flink.yarn.ApplicationClient - Sending StopYarnSession request to ApplicationMaster.
16:54:58,391 INFO org.apache.flink.yarn.ApplicationClient - Remote JobManager has been stopped successfully. Stopping local application client
16:54:58,392 INFO org.apache.flink.yarn.ApplicationClient - Stopped Application client.
16:54:58,392 INFO org.apache.flink.yarn.ApplicationClient - Disconnect from JobManager Actor[akka.tcp://flink@10.180.86.100:45496/user/jobmanager#-344327648].
16:54:58,407 INFO org.apache.flink.yarn.FlinkYarnCluster - Deleting files in hdfs://ip-10-5-190-199.ec2.internal:8020/user/hadoop/.flink/application_1452097713191_0002
16:54:58,409 INFO org.apache.flink.yarn.FlinkYarnCluster - Application application_1452097713191_0002 finished with state FINISHED and final state SUCCEEDED at 1452099298232
16:54:59,147 INFO org.apache.flink.yarn.FlinkYarnCluster - YARN Client is shutting down
Wow that worked! 2 things to note:
- You need to set HADOOP_CONF_DIR so Flink knows how to connect to HDFS
- You do NOT need to install Flink “cluster-wide” or anything like that!
Because Flink uses Yarn to launch itself, you don’t need to have JAR files deployed to your cluster. Nice and simple.
Let’s see if we can read direct from S3 like we can when using MapReduce.
Using Flink and S3 on EMR
Should be easy enough…
[hadoop@ip-10-5-190-199 ~]$ HADOOP_CONF_DIR=/etc/hadoop/conf flink-0.10.1/bin/flink run -m yarn-cluster -yn 3 -yjm 1024 -ytm 4096 flink-0.10.1/examples/WordCount.jar s3://elasticmapreduce/samples/wordcount/input/0001 hdfs:///flink-output-2
YARN cluster mode detected. Switching Log4j output to console
16:59:17,865 INFO org.apache.hadoop.yarn.client.RMProxy - Connecting to ResourceManager at ip-10-5-190-199.ec2.internal/10.5.190.199:8032
16:59:18,103 INFO org.apache.flink.client.FlinkYarnSessionCli - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.FlinkYarnClient to locate the jar
16:59:18,114 INFO org.apache.flink.yarn.FlinkYarnClient - Using values:
16:59:18,116 INFO org.apache.flink.yarn.FlinkYarnClient - TaskManager count = 3
16:59:18,116 INFO org.apache.flink.yarn.FlinkYarnClient - JobManager memory = 1024
16:59:18,116 INFO org.apache.flink.yarn.FlinkYarnClient - TaskManager memory = 4096
16:59:18,751 INFO org.apache.flink.yarn.Utils - Copying from file:/home/hadoop/flink-0.10.1/lib/flink-dist_2.11-0.10.1.jar to hdfs://ip-10-5-190-199.ec2.internal:8020/user/hadoop/.flink/application_1452097713191_0004/flink-dist_2.11-0.10.1.jar
16:59:19,515 INFO org.apache.flink.yarn.Utils - Copying from /home/hadoop/flink-0.10.1/conf/flink-conf.yaml to hdfs://ip-10-5-190-199.ec2.internal:8020/user/hadoop/.flink/application_1452097713191_0004/flink-conf.yaml
16:59:19,532 INFO org.apache.flink.yarn.Utils - Copying from file:/home/hadoop/flink-0.10.1/conf/logback.xml to hdfs://ip-10-5-190-199.ec2.internal:8020/user/hadoop/.flink/application_1452097713191_0004/logback.xml
16:59:19,556 INFO org.apache.flink.yarn.Utils - Copying from file:/home/hadoop/flink-0.10.1/conf/log4j.properties to hdfs://ip-10-5-190-199.ec2.internal:8020/user/hadoop/.flink/application_1452097713191_0004/log4j.properties
16:59:19,581 INFO org.apache.flink.yarn.FlinkYarnClient - Submitting application master application_1452097713191_0004
16:59:19,604 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl - Submitted application application_1452097713191_0004
16:59:19,604 INFO org.apache.flink.yarn.FlinkYarnClient - Waiting for the cluster to be allocated
16:59:19,606 INFO org.apache.flink.yarn.FlinkYarnClient - Deploying cluster, current state ACCEPTED
16:59:20,608 INFO org.apache.flink.yarn.FlinkYarnClient - Deploying cluster, current state ACCEPTED
16:59:21,610 INFO org.apache.flink.yarn.FlinkYarnClient - Deploying cluster, current state ACCEPTED
16:59:22,612 INFO org.apache.flink.yarn.FlinkYarnClient - Deploying cluster, current state ACCEPTED
16:59:23,614 INFO org.apache.flink.yarn.FlinkYarnClient - YARN application has been deployed successfully.
16:59:23,619 INFO org.apache.flink.yarn.FlinkYarnCluster - Start actor system.
16:59:24,187 INFO org.apache.flink.yarn.FlinkYarnCluster - Start application client.
YARN cluster started
JobManager web interface address http://ip-10-5-190-199.ec2.internal:20888/proxy/application_1452097713191_0004/
Waiting until all TaskManagers have connected
16:59:24,200 INFO org.apache.flink.yarn.ApplicationClient - Notification about new leader address akka.tcp://flink@10.139.94.101:59300/user/jobmanager with session ID null.
No status updates from the YARN cluster received so far. Waiting ...
16:59:24,204 INFO org.apache.flink.yarn.ApplicationClient - Received address of new leader akka.tcp://flink@10.139.94.101:59300/user/jobmanager with session ID null.
16:59:24,205 INFO org.apache.flink.yarn.ApplicationClient - Disconnect from JobManager null.
16:59:24,209 INFO org.apache.flink.yarn.ApplicationClient - Trying to register at JobManager akka.tcp://flink@10.139.94.101:59300/user/jobmanager.
16:59:24,400 INFO org.apache.flink.yarn.ApplicationClient - Successfully registered at the JobManager Actor[akka.tcp://flink@10.139.94.101:59300/user/jobmanager#1775740195]
TaskManager status (0/3)
TaskManager status (0/3)
TaskManager status (0/3)
TaskManager status (0/3)
TaskManager status (0/3)
TaskManager status (0/3)
TaskManager status (0/3)
TaskManager status (0/3)
TaskManager status (0/3)
TaskManager status (0/3)
TaskManager status (0/3)
TaskManager status (0/3)
TaskManager status (1/3)
TaskManager status (1/3)
TaskManager status (1/3)
TaskManager status (1/3)
All TaskManagers are connected
Using the parallelism provided by the remote cluster (3). To use another parallelism, set it at the ./bin/flink client.
org.apache.flink.client.program.ProgramInvocationException: The program execution failed: Failed to submit job 8aa2583eba2dc27da5133dbc34eb1181 (WordCount Example)
at org.apache.flink.client.program.Client.runBlocking(Client.java:370)
at org.apache.flink.client.program.Client.runBlocking(Client.java:348)
at org.apache.flink.client.program.Client.runBlocking(Client.java:315)
at org.apache.flink.client.program.ContextEnvironment.execute(ContextEnvironment.java:70)
at org.apache.flink.examples.java.wordcount.WordCount.main(WordCount.java:78)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.apache.flink.client.program.PackagedProgram.callMainMethod(PackagedProgram.java:497)
at org.apache.flink.client.program.PackagedProgram.invokeInteractiveModeForExecution(PackagedProgram.java:395)
at org.apache.flink.client.program.Client.runBlocking(Client.java:252)
at org.apache.flink.client.CliFrontend.executeProgramBlocking(CliFrontend.java:676)
at org.apache.flink.client.CliFrontend.run(CliFrontend.java:326)
at org.apache.flink.client.CliFrontend.parseParameters(CliFrontend.java:978)
at org.apache.flink.client.CliFrontend.main(CliFrontend.java:1028)
Caused by: org.apache.flink.runtime.client.JobExecutionException: Failed to submit job 8aa2583eba2dc27da5133dbc34eb1181 (WordCount Example)
at org.apache.flink.runtime.jobmanager.JobManager.org$apache$flink$runtime$jobmanager$JobManager$$submitJob(JobManager.scala:952)
at org.apache.flink.runtime.jobmanager.JobManager$$anonfun$handleMessage$1.applyOrElse(JobManager.scala:341)
at scala.runtime.AbstractPartialFunction.apply(AbstractPartialFunction.scala:36)
at org.apache.flink.yarn.YarnJobManager$$anonfun$handleYarnMessage$1.applyOrElse(YarnJobManager.scala:152)
at scala.PartialFunction$OrElse.apply(PartialFunction.scala:167)
at org.apache.flink.runtime.LeaderSessionMessageFilter$$anonfun$receive$1.applyOrElse(LeaderSessionMessageFilter.scala:36)
at scala.runtime.AbstractPartialFunction.apply(AbstractPartialFunction.scala:36)
at org.apache.flink.runtime.LogMessages$$anon$1.apply(LogMessages.scala:33)
at org.apache.flink.runtime.LogMessages$$anon$1.apply(LogMessages.scala:28)
at scala.PartialFunction$class.applyOrElse(PartialFunction.scala:123)
at org.apache.flink.runtime.LogMessages$$anon$1.applyOrElse(LogMessages.scala:28)
at akka.actor.Actor$class.aroundReceive(Actor.scala:465)
at org.apache.flink.runtime.jobmanager.JobManager.aroundReceive(JobManager.scala:100)
at akka.actor.ActorCell.receiveMessage(ActorCell.scala:516)
at akka.actor.ActorCell.invoke(ActorCell.scala:487)
at akka.dispatch.Mailbox.processMailbox(Mailbox.scala:254)
at akka.dispatch.Mailbox.run(Mailbox.scala:221)
at akka.dispatch.Mailbox.exec(Mailbox.scala:231)
at scala.concurrent.forkjoin.ForkJoinTask.doExec(ForkJoinTask.java:260)
at scala.concurrent.forkjoin.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1339)
at scala.concurrent.forkjoin.ForkJoinPool.runWorker(ForkJoinPool.java:1979)
at scala.concurrent.forkjoin.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:107)
Caused by: org.apache.flink.runtime.JobException: Creating the input splits caused an error: org.apache.http.impl.client.DefaultHttpClient.execute(Lorg/apache/http/client/methods/HttpUriRequest;)Lorg/apache/http/client/methods/CloseableHttpResponse;
at org.apache.flink.runtime.executiongraph.ExecutionJobVertex.<init>(ExecutionJobVertex.java:168)
at org.apache.flink.runtime.executiongraph.ExecutionGraph.attachJobGraph(ExecutionGraph.java:640)
at org.apache.flink.runtime.jobmanager.JobManager.org$apache$flink$runtime$jobmanager$JobManager$$submitJob(JobManager.scala:878)
... 21 more
Caused by: java.lang.NoSuchMethodError: org.apache.http.impl.client.DefaultHttpClient.execute(Lorg/apache/http/client/methods/HttpUriRequest;)Lorg/apache/http/client/methods/CloseableHttpResponse;
at amazon.emr.metrics.ClientUtil.getInstanceId(ClientUtil.java:115)
at amazon.emr.metrics.MetricsConfig.getInstanceId(MetricsConfig.java:294)
at amazon.emr.metrics.MetricsConfig.<init>(MetricsConfig.java:195)
at amazon.emr.metrics.MetricsConfig.<init>(MetricsConfig.java:182)
at amazon.emr.metrics.MetricsConfig.<init>(MetricsConfig.java:177)
at amazon.emr.metrics.MetricsSaver.ensureSingleton(MetricsSaver.java:652)
at amazon.emr.metrics.MetricsSaver.addInternal(MetricsSaver.java:332)
at amazon.emr.metrics.MetricsSaver.addValue(MetricsSaver.java:178)
at com.amazon.ws.emr.hadoop.fs.metrics.ClusterMetrics.addCount(ClusterMetrics.java:39)
at com.amazon.ws.emr.core.metrics.Metrics.addCount(Metrics.java:12)
at com.amazon.ws.emr.hadoop.fs.EmrFileSystem.initialize(EmrFileSystem.java:114)
at org.apache.flink.runtime.fs.hdfs.HadoopFileSystem.initialize(HadoopFileSystem.java:321)
at org.apache.flink.core.fs.FileSystem.get(FileSystem.java:236)
at org.apache.flink.core.fs.Path.getFileSystem(Path.java:309)
at org.apache.flink.api.common.io.FileInputFormat.createInputSplits(FileInputFormat.java:449)
at org.apache.flink.api.common.io.FileInputFormat.createInputSplits(FileInputFormat.java:57)
at org.apache.flink.runtime.executiongraph.ExecutionJobVertex.<init>(ExecutionJobVertex.java:152)
... 23 more
The exception above occurred while trying to run your command.
The following messages were created by the YARN cluster while running the Job:
[Wed Jan 06 16:59:24 UTC 2016] Launching container (container_1452097713191_0004_01_000002 on host ip-10-180-86-100.ec2.internal).
[Wed Jan 06 16:59:25 UTC 2016] Launching container (container_1452097713191_0004_01_000003 on host ip-10-139-94-101.ec2.internal).
[Wed Jan 06 16:59:25 UTC 2016] Launching container (container_1452097713191_0004_01_000004 on host ip-10-180-86-100.ec2.internal).
Shutting down YARN cluster
16:59:34,562 INFO org.apache.flink.yarn.FlinkYarnCluster - Sending shutdown request to the Application Master
16:59:34,563 INFO org.apache.flink.yarn.ApplicationClient - Sending StopYarnSession request to ApplicationMaster.
16:59:34,816 INFO org.apache.flink.yarn.ApplicationClient - Remote JobManager has been stopped successfully. Stopping local application client
16:59:34,817 INFO org.apache.flink.yarn.ApplicationClient - Stopped Application client.
16:59:34,817 INFO org.apache.flink.yarn.ApplicationClient - Disconnect from JobManager Actor[akka.tcp://flink@10.139.94.101:59300/user/jobmanager#1775740195].
16:59:34,835 INFO org.apache.flink.yarn.FlinkYarnCluster - Deleting files in hdfs://ip-10-5-190-199.ec2.internal:8020/user/hadoop/.flink/application_1452097713191_0004
16:59:34,837 INFO org.apache.flink.yarn.FlinkYarnCluster - Application application_1452097713191_0004 finished with state FINISHED and final state FAILED at 1452099574573
16:59:35,209 INFO org.apache.flink.yarn.FlinkYarnCluster - YARN Client is shutting down
Oh no, what happened! Flink is shipped with an incompatible version of org.apache.httpcomponents:httpcore and org.apache.httpcomponents:httpclient which conflict with the proprietary EMRFS S3 implementation. For reference, Flink is using this in its pom.xml:
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpcore</artifactId>
<version>4.2.5</version>
</dependency>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.2.6</version>
</dependency>
I’m going to try and get a PR into Flink to fix this, but in the meantime, there is an easy workaround. Let’s call it the “nuclear option”.
[hadoop@ip-10-5-190-199 ~]$ zip --delete flink-0.10.1/lib/flink-dist_2.11-0.10.1.jar "org/apache/http/*"
deleting: org/apache/http/
deleting: org/apache/http/cookie/
deleting: org/apache/http/cookie/CookiePathComparator.class
deleting: org/apache/http/cookie/CookieRestrictionViolationException.class
deleting: org/apache/http/cookie/SetCookie.class
deleting: org/apache/http/cookie/SM.class
deleting: org/apache/http/cookie/CookieAttributeHandler.class
deleting: org/apache/http/cookie/CookieSpecFactory.class
deleting: org/apache/http/cookie/SetCookie2.class
...
Ok now we’ve removed the bad versions… let’s link in some good versions.
[hadoop@ip-10-5-190-199 ~]$ ln -s /usr/lib/hadoop/lib/httpclient-4.3.4.jar flink-0.10.1/lib/httpclient-4.3.4.jar
[hadoop@ip-10-5-190-199 ~]$ ln -s /usr/lib/hadoop/lib/httpcore-4.3.2.jar flink-0.10.1/lib/httpcore-4.3.2.jar
Let’s try again:
[hadoop@ip-10-5-190-199 ~]$ HADOOP_CONF_DIR=/etc/hadoop/conf flink-0.10.1/bin/flink run -m yarn-cluster -yn 3 -yjm 1024 -ytm 4096 flink-0.10.1/examples/WordCount.jar s3://elasticmapreduce/samples/wordcount/input/0001 hdfs:///flink-output-3
YARN cluster mode detected. Switching Log4j output to console
17:08:45,335 INFO org.apache.hadoop.yarn.client.RMProxy - Connecting to ResourceManager at ip-10-5-190-199.ec2.internal/10.5.190.199:8032
17:08:45,528 INFO org.apache.flink.client.FlinkYarnSessionCli - No path for the flink jar passed. Using the location of class org.apache.flink.yarn.FlinkYarnClient to locate the jar
17:08:45,541 INFO org.apache.flink.yarn.FlinkYarnClient - Using values:
17:08:45,543 INFO org.apache.flink.yarn.FlinkYarnClient - TaskManager count = 3
17:08:45,543 INFO org.apache.flink.yarn.FlinkYarnClient - JobManager memory = 1024
17:08:45,543 INFO org.apache.flink.yarn.FlinkYarnClient - TaskManager memory = 4096
17:08:46,220 INFO org.apache.flink.yarn.Utils - Copying from file:/home/hadoop/flink-0.10.1/lib/flink-dist_2.11-0.10.1.jar to hdfs://ip-10-5-190-199.ec2.internal:8020/user/hadoop/.flink/application_1452097713191_0005/flink-dist_2.11-0.10.1.jar
17:08:47,105 INFO org.apache.flink.yarn.Utils - Copying from /home/hadoop/flink-0.10.1/conf/flink-conf.yaml to hdfs://ip-10-5-190-199.ec2.internal:8020/user/hadoop/.flink/application_1452097713191_0005/flink-conf.yaml
17:08:47,118 INFO org.apache.flink.yarn.Utils - Copying from file:/home/hadoop/flink-0.10.1/conf/logback.xml to hdfs://ip-10-5-190-199.ec2.internal:8020/user/hadoop/.flink/application_1452097713191_0005/logback.xml
17:08:47,132 INFO org.apache.flink.yarn.Utils - Copying from file:/home/hadoop/flink-0.10.1/conf/log4j.properties to hdfs://ip-10-5-190-199.ec2.internal:8020/user/hadoop/.flink/application_1452097713191_0005/log4j.properties
17:08:47,153 INFO org.apache.flink.yarn.FlinkYarnClient - Submitting application master application_1452097713191_0005
17:08:47,177 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl - Submitted application application_1452097713191_0005
17:08:47,178 INFO org.apache.flink.yarn.FlinkYarnClient - Waiting for the cluster to be allocated
17:08:47,179 INFO org.apache.flink.yarn.FlinkYarnClient - Deploying cluster, current state ACCEPTED
17:08:48,181 INFO org.apache.flink.yarn.FlinkYarnClient - Deploying cluster, current state ACCEPTED
17:08:49,183 INFO org.apache.flink.yarn.FlinkYarnClient - Deploying cluster, current state ACCEPTED
17:08:50,185 INFO org.apache.flink.yarn.FlinkYarnClient - Deploying cluster, current state ACCEPTED
17:08:51,187 INFO org.apache.flink.yarn.FlinkYarnClient - Deploying cluster, current state ACCEPTED
17:08:52,188 INFO org.apache.flink.yarn.FlinkYarnClient - YARN application has been deployed successfully.
17:08:52,192 INFO org.apache.flink.yarn.FlinkYarnCluster - Start actor system.
17:08:52,788 INFO org.apache.flink.yarn.FlinkYarnCluster - Start application client.
YARN cluster started
JobManager web interface address http://ip-10-5-190-199.ec2.internal:20888/proxy/application_1452097713191_0005/
Waiting until all TaskManagers have connected
17:08:52,801 INFO org.apache.flink.yarn.ApplicationClient - Notification about new leader address akka.tcp://flink@10.180.86.100:58229/user/jobmanager with session ID null.
No status updates from the YARN cluster received so far. Waiting ...
17:08:52,805 INFO org.apache.flink.yarn.ApplicationClient - Received address of new leader akka.tcp://flink@10.180.86.100:58229/user/jobmanager with session ID null.
17:08:52,806 INFO org.apache.flink.yarn.ApplicationClient - Disconnect from JobManager null.
17:08:52,809 INFO org.apache.flink.yarn.ApplicationClient - Trying to register at JobManager akka.tcp://flink@10.180.86.100:58229/user/jobmanager.
17:08:53,036 INFO org.apache.flink.yarn.ApplicationClient - Successfully registered at the JobManager Actor[akka.tcp://flink@10.180.86.100:58229/user/jobmanager#-89275098]
TaskManager status (0/3)
TaskManager status (0/3)
TaskManager status (0/3)
TaskManager status (0/3)
TaskManager status (0/3)
TaskManager status (0/3)
TaskManager status (0/3)
TaskManager status (0/3)
TaskManager status (0/3)
TaskManager status (0/3)
TaskManager status (0/3)
TaskManager status (0/3)
TaskManager status (1/3)
TaskManager status (1/3)
TaskManager status (1/3)
TaskManager status (1/3)
All TaskManagers are connected
Using the parallelism provided by the remote cluster (3). To use another parallelism, set it at the ./bin/flink client.
01/06/2016 17:09:03 Job execution switched to status RUNNING.
01/06/2016 17:09:03 CHAIN DataSource (at getTextDataSet(WordCount.java:142) (org.apache.flink.api.java.io.TextInputFormat)) -> FlatMap (FlatMap at main(WordCount.java:69)) -> Combine(SUM(1), at main(WordCount.java:72)(1/3) switched to SCHEDULED
01/06/2016 17:09:03 CHAIN DataSource (at getTextDataSet(WordCount.java:142) (org.apache.flink.api.java.io.TextInputFormat)) -> FlatMap (FlatMap at main(WordCount.java:69)) -> Combine(SUM(1), at main(WordCount.java:72)(1/3) switched to DEPLOYING
01/06/2016 17:09:03 CHAIN DataSource (at getTextDataSet(WordCount.java:142) (org.apache.flink.api.java.io.TextInputFormat)) -> FlatMap (FlatMap at main(WordCount.java:69)) -> Combine(SUM(1), at main(WordCount.java:72)(2/3) switched to SCHEDULED
01/06/2016 17:09:03 CHAIN DataSource (at getTextDataSet(WordCount.java:142) (org.apache.flink.api.java.io.TextInputFormat)) -> FlatMap (FlatMap at main(WordCount.java:69)) -> Combine(SUM(1), at main(WordCount.java:72)(2/3) switched to DEPLOYING
01/06/2016 17:09:03 CHAIN DataSource (at getTextDataSet(WordCount.java:142) (org.apache.flink.api.java.io.TextInputFormat)) -> FlatMap (FlatMap at main(WordCount.java:69)) -> Combine(SUM(1), at main(WordCount.java:72)(3/3) switched to SCHEDULED
01/06/2016 17:09:03 CHAIN DataSource (at getTextDataSet(WordCount.java:142) (org.apache.flink.api.java.io.TextInputFormat)) -> FlatMap (FlatMap at main(WordCount.java:69)) -> Combine(SUM(1), at main(WordCount.java:72)(3/3) switched to DEPLOYING
01/06/2016 17:09:04 CHAIN DataSource (at getTextDataSet(WordCount.java:142) (org.apache.flink.api.java.io.TextInputFormat)) -> FlatMap (FlatMap at main(WordCount.java:69)) -> Combine(SUM(1), at main(WordCount.java:72)(1/3) switched to RUNNING
01/06/2016 17:09:04 CHAIN DataSource (at getTextDataSet(WordCount.java:142) (org.apache.flink.api.java.io.TextInputFormat)) -> FlatMap (FlatMap at main(WordCount.java:69)) -> Combine(SUM(1), at main(WordCount.java:72)(3/3) switched to RUNNING
01/06/2016 17:09:04 CHAIN DataSource (at getTextDataSet(WordCount.java:142) (org.apache.flink.api.java.io.TextInputFormat)) -> FlatMap (FlatMap at main(WordCount.java:69)) -> Combine(SUM(1), at main(WordCount.java:72)(2/3) switched to RUNNING
01/06/2016 17:09:07 Reduce (SUM(1), at main(WordCount.java:72)(1/3) switched to SCHEDULED
01/06/2016 17:09:07 Reduce (SUM(1), at main(WordCount.java:72)(3/3) switched to SCHEDULED
01/06/2016 17:09:07 Reduce (SUM(1), at main(WordCount.java:72)(1/3) switched to DEPLOYING
01/06/2016 17:09:07 Reduce (SUM(1), at main(WordCount.java:72)(3/3) switched to DEPLOYING
01/06/2016 17:09:07 Reduce (SUM(1), at main(WordCount.java:72)(2/3) switched to SCHEDULED
01/06/2016 17:09:07 Reduce (SUM(1), at main(WordCount.java:72)(2/3) switched to DEPLOYING
01/06/2016 17:09:07 Reduce (SUM(1), at main(WordCount.java:72)(2/3) switched to RUNNING
01/06/2016 17:09:07 Reduce (SUM(1), at main(WordCount.java:72)(3/3) switched to RUNNING
01/06/2016 17:09:07 Reduce (SUM(1), at main(WordCount.java:72)(1/3) switched to RUNNING
01/06/2016 17:09:07 CHAIN DataSource (at getTextDataSet(WordCount.java:142) (org.apache.flink.api.java.io.TextInputFormat)) -> FlatMap (FlatMap at main(WordCount.java:69)) -> Combine(SUM(1), at main(WordCount.java:72)(1/3) switched to FINISHED
01/06/2016 17:09:09 CHAIN DataSource (at getTextDataSet(WordCount.java:142) (org.apache.flink.api.java.io.TextInputFormat)) -> FlatMap (FlatMap at main(WordCount.java:69)) -> Combine(SUM(1), at main(WordCount.java:72)(2/3) switched to FINISHED
01/06/2016 17:09:10 CHAIN DataSource (at getTextDataSet(WordCount.java:142) (org.apache.flink.api.java.io.TextInputFormat)) -> FlatMap (FlatMap at main(WordCount.java:69)) -> Combine(SUM(1), at main(WordCount.java:72)(3/3) switched to FINISHED
01/06/2016 17:09:10 DataSink (CsvOutputFormat (path: hdfs:/flink-output-3, delimiter: ))(2/3) switched to SCHEDULED
01/06/2016 17:09:10 DataSink (CsvOutputFormat (path: hdfs:/flink-output-3, delimiter: ))(2/3) switched to DEPLOYING
01/06/2016 17:09:10 Reduce (SUM(1), at main(WordCount.java:72)(2/3) switched to FINISHED
01/06/2016 17:09:10 DataSink (CsvOutputFormat (path: hdfs:/flink-output-3, delimiter: ))(2/3) switched to RUNNING
01/06/2016 17:09:10 DataSink (CsvOutputFormat (path: hdfs:/flink-output-3, delimiter: ))(1/3) switched to SCHEDULED
01/06/2016 17:09:10 DataSink (CsvOutputFormat (path: hdfs:/flink-output-3, delimiter: ))(1/3) switched to DEPLOYING
01/06/2016 17:09:10 DataSink (CsvOutputFormat (path: hdfs:/flink-output-3, delimiter: ))(3/3) switched to SCHEDULED
01/06/2016 17:09:10 DataSink (CsvOutputFormat (path: hdfs:/flink-output-3, delimiter: ))(3/3) switched to DEPLOYING
01/06/2016 17:09:10 DataSink (CsvOutputFormat (path: hdfs:/flink-output-3, delimiter: ))(1/3) switched to RUNNING
01/06/2016 17:09:10 DataSink (CsvOutputFormat (path: hdfs:/flink-output-3, delimiter: ))(3/3) switched to RUNNING
01/06/2016 17:09:10 Reduce (SUM(1), at main(WordCount.java:72)(1/3) switched to FINISHED
01/06/2016 17:09:10 Reduce (SUM(1), at main(WordCount.java:72)(3/3) switched to FINISHED
01/06/2016 17:09:11 DataSink (CsvOutputFormat (path: hdfs:/flink-output-3, delimiter: ))(2/3) switched to FINISHED
01/06/2016 17:09:11 DataSink (CsvOutputFormat (path: hdfs:/flink-output-3, delimiter: ))(3/3) switched to FINISHED
01/06/2016 17:09:11 DataSink (CsvOutputFormat (path: hdfs:/flink-output-3, delimiter: ))(1/3) switched to FINISHED
01/06/2016 17:09:11 Job execution switched to status FINISHED.
Shutting down YARN cluster
17:09:11,603 INFO org.apache.flink.yarn.FlinkYarnCluster - Sending shutdown request to the Application Master
17:09:11,604 INFO org.apache.flink.yarn.ApplicationClient - Sending StopYarnSession request to ApplicationMaster.
17:09:11,823 INFO org.apache.flink.yarn.ApplicationClient - Remote JobManager has been stopped successfully. Stopping local application client
17:09:11,824 INFO org.apache.flink.yarn.ApplicationClient - Stopped Application client.
17:09:11,825 INFO org.apache.flink.yarn.ApplicationClient - Disconnect from JobManager Actor[akka.tcp://flink@10.180.86.100:58229/user/jobmanager#-89275098].
17:09:11,839 INFO org.apache.flink.yarn.FlinkYarnCluster - Deleting files in hdfs://ip-10-5-190-199.ec2.internal:8020/user/hadoop/.flink/application_1452097713191_0005
17:09:11,841 INFO org.apache.flink.yarn.FlinkYarnCluster - Application application_1452097713191_0005 finished with state FINISHED and final state SUCCEEDED at 1452100151614
17:09:12,824 INFO org.apache.flink.yarn.FlinkYarnCluster - YARN Client is shutting down
It worked!
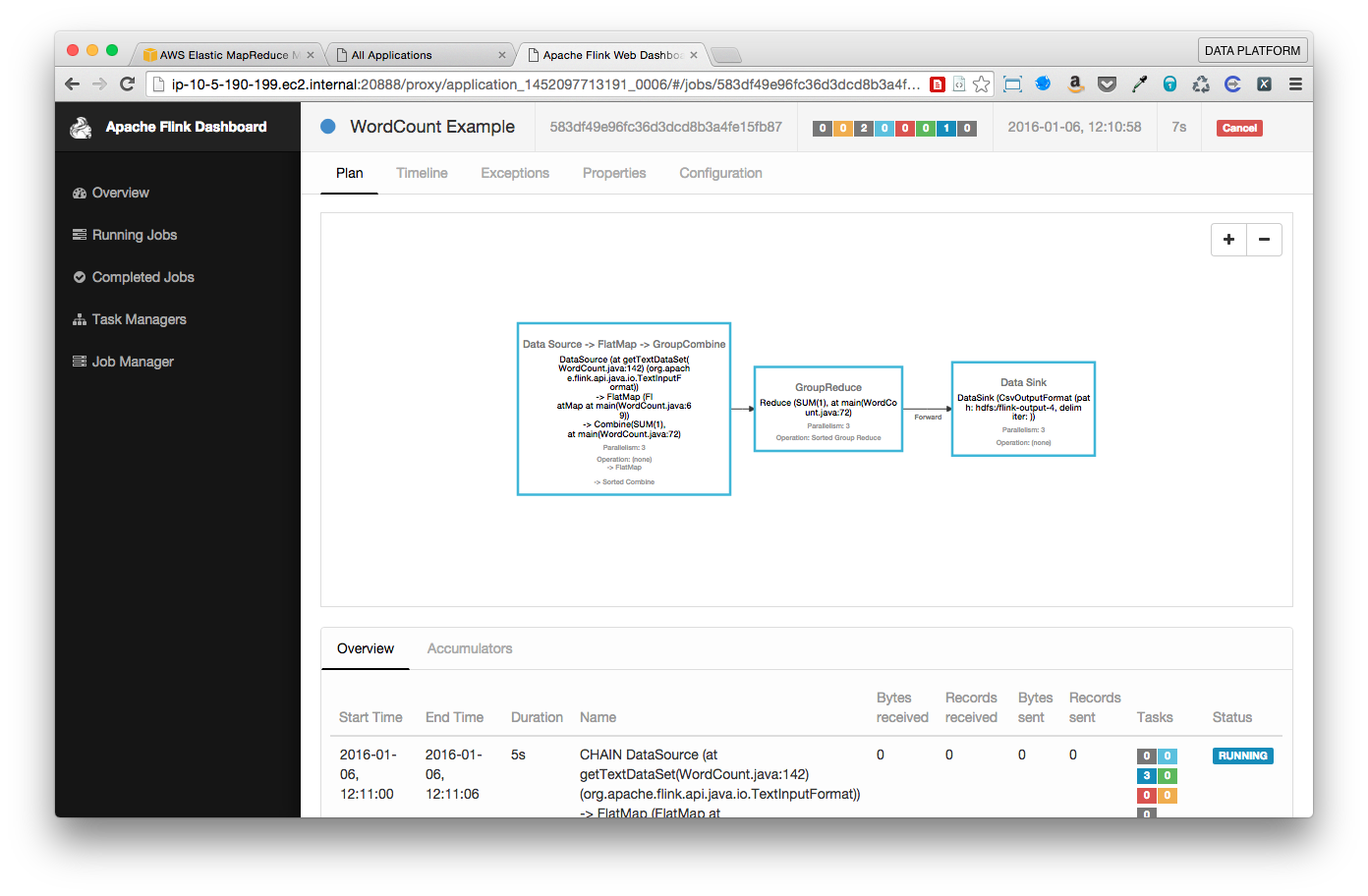
Conclusion
I am super excited about Flink and really hope that we can get Flink on EMR soon. It’s ability to be a drop-in replacement for Mapreduce and existing Scalding jobs is exciting and the ease in which you can run it on YARN makes it a really compelling alternative to Tez.