Running Scalding jobs on Apache Flink
My previous post showed a very simple Scalding workflow. Apache Flink is a real time streaming framework that’s very promising. It also supports running Cascading workflows with very little modification.
Surely there must be some way to run a Scalding job on top of Flink? Turns out… YES!
In a nutshell
Here are the high-level things we need to solve for
- We need a Scalding job to test this out with
cascading-flinkrequires Cascading 3- We need a new version of Scalding
– Compiled against Cascading 3
– Allows
hadoop2-flinkto be selected as the Cascading “fabric” - There is a bug in Twitter Chill
- We need Flink packaged with the Chill fix
Scalding job
Let’s start with a very simple Scalding job. You can download https://github.com/themodernlife/simple-scalding-example for some inspiration.
package net.themodernlife
import com.twitter.scalding._
class WordCount(args: Args) extends Job(args) {
def tokenize(text: String): Array[String] = {
text.toLowerCase.replaceAll("[^a-zA-Z0-9\\s]", "").split("\\s+")
}
val input = args("input")
val output = args("output")
TextLine(args("input"))
.flatMap[String, String]('line → 'word)(tokenize)
.groupBy('word)(_.size)
.write(Tsv(output))
}
We’ll be making some updates to our build.sbt. Here’s what we’re starting with
organization := "net.themodernlife"
name := "simple-scalding-example"
scalaVersion := "2.11.7"
scalacOptions ++= Seq("-encoding", "utf-8", "-deprecation", "-unchecked", "-feature")
resolvers ++= Seq(
"Concurrent Maven Repo" at "http://conjars.org/repo",
"Twitter Maven Repo" at "http://maven.twttr.com"
)
libraryDependencies ++= Seq(
"com.twitter" %% "scalding-core" % "0.15.0",
"org.apache.hadoop" % "hadoop-client" % "2.2.0" % "provided",
"org.slf4j" % "slf4j-log4j12" % "1.7.13" % "provided"
)
A new Scalding build
We need to update Scalding
- Apply https://github.com/twitter/scalding/pull/1446
- Apply/hack https://github.com/twitter/scalding/pull/1220
- Hack
Build.scalato ignore some submodules
According to http://www.cascading.org/2015/09/22/announcing-cascading-on-apache-flink/,
cascading-flink only works with the Cascading 3 API. Scalding hasn’t been updated yet,
but there is a PR which updates most of the code to work with Cascading 3’s newer APIs
at https://github.com/twitter/scalding/pull/1446.
Unfortunately, this PR requires even more changes to upstream projects for modules such as
scalding-parquet to compile. I don’t use those modules, so I’m just going to hack the Scalding build so it doesn’t compile those modules.
Finally, when running Cascading we need to provide a “fabric” selection. To date, the only options have been Hadoop and Local mode, but with execution frameworks like Tez on the horizon there has been some movement to make this even more configurable.
The PR at https://github.com/twitter/scalding/pull/1220 adds Tez as a backend, so we’ll just extend that PR to add Flink too.
My fork of Scalding at https://github.com/themodernlife/scalding/tree/scalding-on-flink has a branch scalding-on-flink you can download and build. You can see the changes necessary by checking out https://github.com/twitter/scalding/compare/develop...themodernlife:scalding-on-flink.
NOTE that Build.scala also has an update for the Chill bug I’ll be describing in a bit…
Now that you have a hacked Scalding, you can publish-local.
$ sbt publish-local
This will install all the Scalding modules with version 0.15.1-SNAPSHOT in your local ivy repo.
Running it the first time
So assuming you’ve applied the patches above and commented out any unnecessary modules, you should be able to try and run things (note that let’s assume you’re using 0.7.1 version of Chill for the moment).
Download Flink from http://flink.apache.org/downloads.html. I’m using 0.10.1 for Hadoop 2.6.0 and Scala 2.11. After downloading and unpacking the tar file at http://www.apache.org/dyn/closer.lua/flink/flink-0.10.1/flink-0.10.1-bin-hadoop26-scala_2.11.tgz we can kick off the Flink daemon.
$ ./start-local.sh
Starting jobmanager daemon on host mm-mac-3270.local.
Now we can load up the dashboard at http://localhost:8081/#/overview to ensure it’s actually running.
To submit a Scalding job to Flink, we need to create a fat jar and update our dependencies a little bit. First, we’ll need to get a copy of the cascading-flink jar and add it to the lib directory in our sbt project. cascading-flink is not currently published to any maven repos that I’m aware of.
You can build it yourself by checking out https://github.com/dataArtisans/cascading-flink and running
$ mvn clean package -DskipTests
The just copy it into lib in your Scalding job project.
Here’s the relevant parts of the new build.sbt
libraryDependencies ++= Seq(
"com.twitter" %% "scalding-core" % "0.15.1-SNAPSHOT" exclude("com.esotericsoftware.minlog", "minlog"),
"org.apache.hadoop" % "hadoop-client" % "2.2.0" % "provided",
"org.slf4j" % "slf4j-log4j12" % "1.7.13" % "provided",
"org.apache.flink" % "flink-clients_2.11" % "0.10.1" % "provided" intransitive()
)
We need to pull in some additional Flink jars, but the way Flink is packaged adds too many transitive dependencies so our assembly task would fail. All those classes can be found when our job is run on the Flink cluster anyways, so I’m not sure why Flink packages them in that jar…
Let’s package our job as a fat jar
$ sbt assembly
OK finally with all that out of the way, we can run it! Let’s just do word count on the README.
$ /tmp/flink-0.10.1/bin/flink run -c com.twitter.scalding.Tool target/scala-2.11/simple-scalding-example-assembly-0.1.1-SNAPSHOT.jar net.themodernlife.WordCount --hadoop2-flink --input README.md --output /tmp/target-output
NOTE how we’re including --hadoop2-flink as the Cascading fabric (instead of the usual --hdfs or --local).
Chill
If you were successfull with everything above, you should get something like
$ /tmp/flink-0.10.1/bin/flink run -c com.twitter.scalding.Tool target/scala-2.11/simple-scalding-example-assembly-0.1.1-SNAPSHOT.jar net.themodernlife.WordCount --hadoop2-flink --input README.md --output /tmp/target-output
org.apache.flink.client.program.ProgramInvocationException: The main method caused an error.
at org.apache.flink.client.program.PackagedProgram.callMainMethod(PackagedProgram.java:512)
at org.apache.flink.client.program.PackagedProgram.invokeInteractiveModeForExecution(PackagedProgram.java:395)
at org.apache.flink.client.program.Client.runBlocking(Client.java:252)
at org.apache.flink.client.CliFrontend.executeProgramBlocking(CliFrontend.java:676)
at org.apache.flink.client.CliFrontend.run(CliFrontend.java:326)
at org.apache.flink.client.CliFrontend.parseParameters(CliFrontend.java:978)
at org.apache.flink.client.CliFrontend.main(CliFrontend.java:1028)
Caused by: java.lang.Throwable: If you know what exactly caused this error, please consider contributing to GitHub via following link.
https://github.com/twitter/scalding/wiki/Common-Exceptions-and-possible-reasons#javalangclassnotfoundexception
at com.twitter.scalding.Tool$.main(Tool.scala:154)
at com.twitter.scalding.Tool.main(Tool.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:497)
at org.apache.flink.client.program.PackagedProgram.callMainMethod(PackagedProgram.java:497)
... 6 more
Caused by: java.lang.reflect.InvocationTargetException
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:422)
at com.twitter.scalding.Job$.apply(Job.scala:45)
at com.twitter.scalding.Tool.getJob(Tool.scala:50)
at com.twitter.scalding.Tool.run(Tool.scala:70)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)
at com.twitter.scalding.Tool$.main(Tool.scala:150)
... 12 more
Caused by: com.twitter.chill.config.ConfigurationException: Could not find class for: com.twitter.scalding.serialization.KryoHadoop
at com.twitter.chill.config.ConfiguredInstantiator.<init>(ConfiguredInstantiator.java:62)
at com.twitter.scalding.Config$class.getKryo(Config.scala:206)
at com.twitter.scalding.Config$$anon$1.getKryo(Config.scala:437)
at com.twitter.scalding.Config$class.getKryoRegisteredClasses(Config.scala:146)
at com.twitter.scalding.Config$$anon$1.getKryoRegisteredClasses(Config.scala:437)
at com.twitter.scalding.Config$class.setSerialization(Config.scala:195)
at com.twitter.scalding.Config$$anon$1.setSerialization(Config.scala:437)
at com.twitter.scalding.Config$.default(Config.scala:424)
at com.twitter.scalding.Config$.defaultFrom(Config.scala:432)
at com.twitter.scalding.Job.name(Job.scala:115)
at com.twitter.scalding.Job.<init>(Job.scala:121)
at net.themodernlife.WordCount.<init>(WordCount.scala:5)
... 21 more
Caused by: java.lang.ClassNotFoundException: com.twitter.scalding.serialization.KryoHadoop
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:331)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:264)
at com.twitter.chill.config.ConfiguredInstantiator.<init>(ConfiguredInstantiator.java:60)
... 32 more
The exception above occurred while trying to run your command.
Oh man! ClassNotFoundException? What’s going on?
Let’s take a small detour into Java class loaders. Chill trys to load classes using reflection, and the line in question is something like this:
KryoInstantiator reflected = null;
try { reflected = reflect((Class<? extends KryoInstantiator>)Class.forName(parts[0]), conf); }
catch(ClassNotFoundException x) {
throw new ConfigurationException("Could not find class for: " + parts[0], x);
}
Class.forName will use the classloader which loaded the current class. This class was loaded into the JVM when Flink first starts up and is in the flink-dist.jar that was downloaded. That classloader cannot see child classes though, so it can’t resolve any classes that might be embeded in the fat jar!
That’s actually a bug, and the code in question should be something like this:
KryoInstantiator reflected = null;
try { reflected = reflect((Class<? extends KryoInstantiator>)Class.forName(parts[0], false, Thread.currentThread().getContextClassLoader()), conf); }
catch(ClassNotFoundException x) {
throw new ConfigurationException("Could not find class for: " + parts[0], x);
}
Now we’re using the classloader for the current thread, which in this case can find classes from the fat jar and therefore can find KryoHadoop.
So what do we need to do? For starters we need a patched version of Chill. But we also need to remove Chill classes from the Flink dist!
Ok, so grab the Chill branch here https://github.com/themodernlife/chill/tree/scalding-on-flink and then do
$ sbt publish-local
If you get errors compiling with Java 8 like [error] (chill-java/compile:doc) javadoc returned nonzero exit code make sure you also add this to Build.scala
javacOptions in doc := Seq("-source", "1.6", "-Xdoclint:none"),
Now we need to build Scalding again, but this time updating the Chill dependency to be 0.7.3-SNAPSHOT (and publish-local).
Finally, we need to DELETE the old chill from flink-dist.jar and replace it with the new Chill build (even though we include Chill/Scalding in our fat jar, Flink core classes still need it too, so it has to be available both on the cluster as well as in our fat jar).
You will need to do
$ zip --delete flink-0.10.1/lib/flink-dist_2.11-0.10.1.jar "com/twitter/chill/*"
And then add the following files (from ~/.ivy2/local) to flink-0.10.1/lib
chill-akka_2.11.jar
chill-algebird_2.11.jar
chill-avro_2.11.jar
chill-bijection_2.11.jar
chill-hadoop.jar
chill-java.jar
chill-protobuf.jar
chill-scrooge_2.11.jar
chill-storm.jar
chill-thrift.jar
chill_2.11.jar
Run it again
Here’s the final relevant portions of our build.sbt
libraryDependencies ++= Seq(
"com.twitter" %% "scalding-core" % "0.15.1-SNAPSHOT" exclude("com.esotericsoftware.minlog", "minlog"),
"org.apache.hadoop" % "hadoop-client" % "2.2.0" % "provided",
"org.slf4j" % "slf4j-log4j12" % "1.7.13" % "provided",
"org.apache.flink" % "flink-clients_2.11" % "0.10.1" % "provided" intransitive()
)
And we can run it
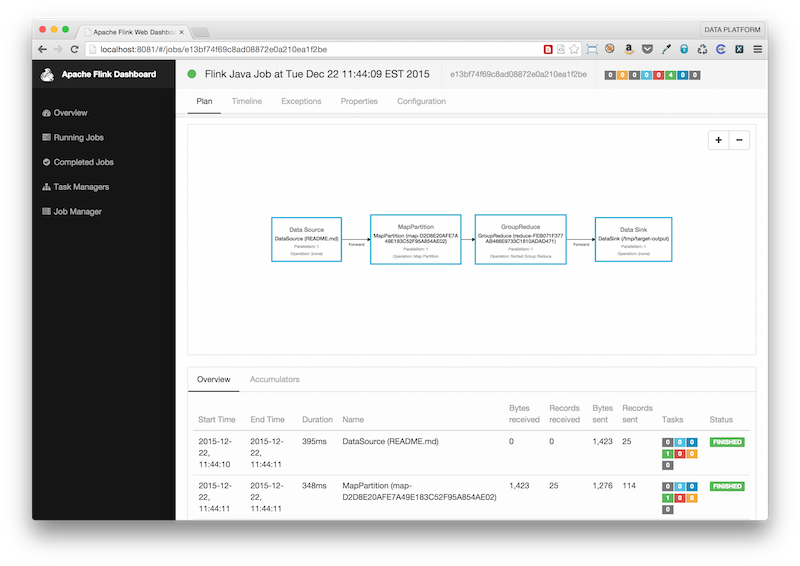
$ /tmp/flink-0.10.1/bin/flink run -c com.twitter.scalding.Tool target/scala-2.11/simple-scalding-example-assembly-0.1.1-SNAPSHOT.jar net.themodernlife.WordCount --hadoop2-flink --input README.md --output /tmp/target-output
11:44:09,792 INFO org.apache.hadoop.conf.Configuration.deprecation - mapred.working.dir is deprecated. Instead, use mapreduce.job.working.dir
11:44:09,792 INFO org.apache.hadoop.conf.Configuration.deprecation - mapred.input.dir is deprecated. Instead, use mapreduce.input.fileinputformat.inputdir
11:44:09,805 INFO org.apache.hadoop.conf.Configuration.deprecation - mapred.job.tracker is deprecated. Instead, use mapreduce.jobtracker.address
11:44:09,957 INFO org.apache.hadoop.conf.Configuration.deprecation - mapred.output.dir is deprecated. Instead, use mapreduce.output.fileoutputformat.outputdir
11:44:09,957 INFO org.apache.hadoop.conf.Configuration.deprecation - mapred.output.compress is deprecated. Instead, use mapreduce.output.fileoutputformat.compress
11:44:09,957 INFO org.apache.hadoop.conf.Configuration.deprecation - mapred.output.key.class is deprecated. Instead, use mapreduce.job.output.key.class
11:44:09,957 INFO org.apache.hadoop.conf.Configuration.deprecation - mapred.output.value.class is deprecated. Instead, use mapreduce.job.output.value.class
12/22/2015 11:44:10 Job execution switched to status RUNNING.
12/22/2015 11:44:10 DataSource (README.md)(1/1) switched to SCHEDULED
12/22/2015 11:44:10 DataSource (README.md)(1/1) switched to DEPLOYING
12/22/2015 11:44:11 DataSource (README.md)(1/1) switched to RUNNING
12/22/2015 11:44:11 MapPartition (map-D2D8E20AFE7A49E183C52F95A854AE02)(1/1) switched to SCHEDULED
12/22/2015 11:44:11 MapPartition (map-D2D8E20AFE7A49E183C52F95A854AE02)(1/1) switched to DEPLOYING
12/22/2015 11:44:11 DataSource (README.md)(1/1) switched to FINISHED
12/22/2015 11:44:11 MapPartition (map-D2D8E20AFE7A49E183C52F95A854AE02)(1/1) switched to RUNNING
12/22/2015 11:44:11 GroupReduce (reduce-FEB071F377AB466E9733C1810ADAD471)(1/1) switched to SCHEDULED
12/22/2015 11:44:11 GroupReduce (reduce-FEB071F377AB466E9733C1810ADAD471)(1/1) switched to DEPLOYING
12/22/2015 11:44:11 MapPartition (map-D2D8E20AFE7A49E183C52F95A854AE02)(1/1) switched to FINISHED
12/22/2015 11:44:11 GroupReduce (reduce-FEB071F377AB466E9733C1810ADAD471)(1/1) switched to RUNNING
12/22/2015 11:44:11 DataSink (/tmp/target-output)(1/1) switched to SCHEDULED
12/22/2015 11:44:11 DataSink (/tmp/target-output)(1/1) switched to DEPLOYING
12/22/2015 11:44:11 GroupReduce (reduce-FEB071F377AB466E9733C1810ADAD471)(1/1) switched to FINISHED
12/22/2015 11:44:11 DataSink (/tmp/target-output)(1/1) switched to RUNNING
12/22/2015 11:44:11 DataSink (/tmp/target-output)(1/1) switched to FINISHED
12/22/2015 11:44:11 Job execution switched to status FINISHED.
You can find the example project at https://github.com/themodernlife/simple-scalding-example/tree/scalding-on-flink
Screenshot: